Orshot is a visual automation platform — businesses use our API and studio to generate images, PDFs, and videos at scale. When our API goes down, our customers' workflows break. That's not acceptable.
Earlier today, our primary hosting provider (Railway) had an outage. Our API was completely unreachable. While the provider recovered within a few hours, it exposed a single point of failure we needed to fix immediately.
What changed
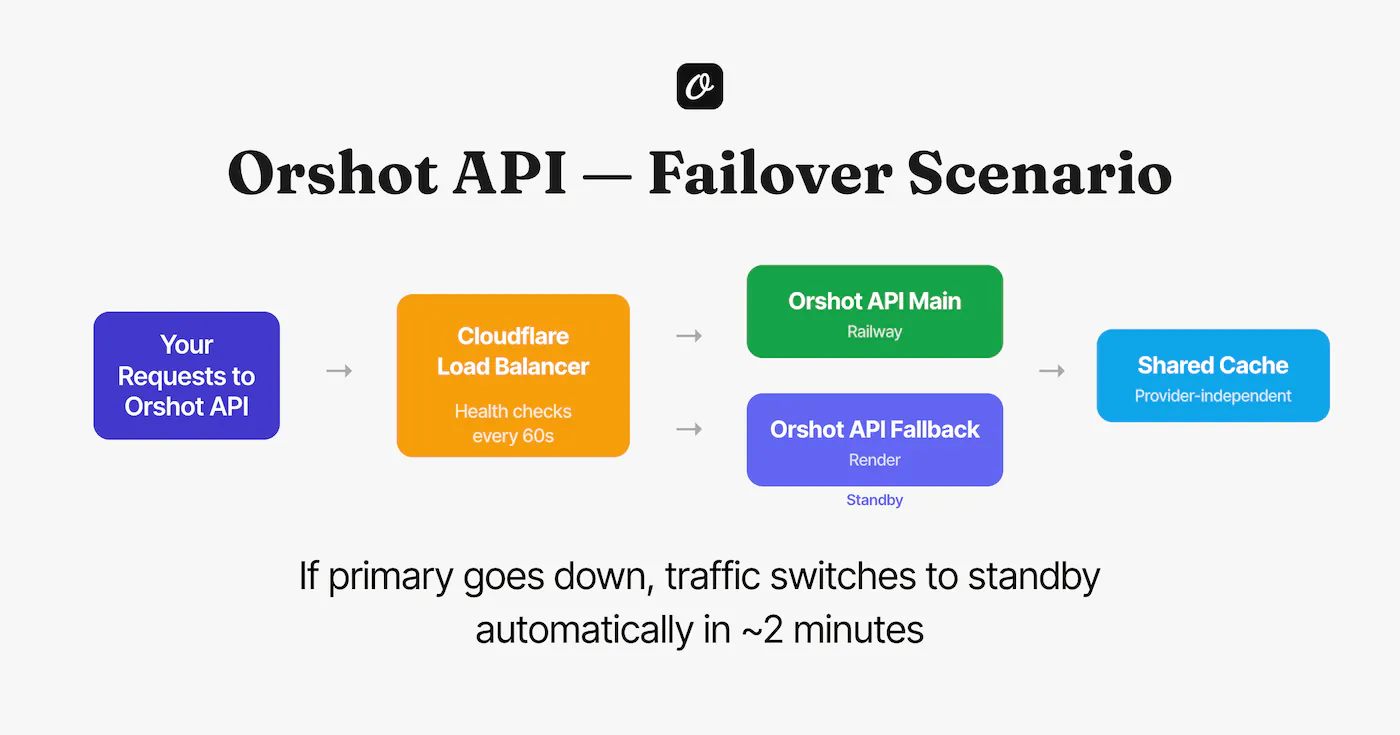
We've moved to a dual-provider architecture with automatic failover:
- Primary API runs on one cloud provider (Railway)
- Standby API runs on a completely separate provider (Render), with its own infrastructure
- Cloudflare Load Balancer sits in front, health-checking both every 60 seconds
- Provider-independent caching via a dedicated managed service — no single provider can take down the cache layer
When the primary goes down, Cloudflare detects the failure and routes all traffic to the standby within ~2 minutes. When the primary recovers, traffic switches back automatically. No manual intervention, no customer impact.
What this means for you
- API calls keep working even during provider outages
- No action needed on your end — the failover is transparent
- Same endpoints, same behavior —
api.orshot.comstays the same
We also migrated our caching layer to a provider-independent managed service, so even partial infrastructure issues at any single provider won't affect response times.
Our commitment
Orshot powers production workflows for agencies, developers, and businesses. Reliability isn't a feature — it's the baseline. This upgrade is part of our ongoing investment in making Orshot infrastructure you can depend on.
If you have questions about our infrastructure or uptime, reach out at hi@orshot.com.